





In brief
- La organización sin fines de lucro Allen Institute for AI presentó Molmo, una familia de modelos de IA multimodal.
- Molmo demostró competencia en la interpretación de datos visuales, desde objetos cotidianos hasta gráficos complejos.
- El sistema fue entrenado con un conjunto de datos curado de casi 1 millón de imágenes, reduciendo los requisitos computacionales.
Alégrense entusiastas de la IA: Hay un nuevo LLM multimodal para que te diviertas.
La organización sin fines de lucro con sede en Seattle, el Allen Institute for AI (Ai2), acaba de presentar Molmo, una familia de modelos de inteligencia artificial multimodal que promete competir con las capacidades de las soluciones propietarias de reconocimiento visual de grandes empresas tecnológicas como OpenAI y Anthropic.
El término "multimodal" se refiere a la capacidad de manejar diferentes tipos de datos, incluyendo texto, imágenes, audio, video e incluso información sensorial.
El martes, Molmo debutó sin los aplausos de todos los modelos de IA importantes pero con todas las características de cualquier modelo de visión de última generación.
El sistema demostró una notable competencia en la interpretación de datos visuales, desde objetos cotidianos hasta gráficos complejos y pizarras desordenadas.
En una demostración en video, Ai2 mostró la capacidad de Molmo para crear agentes de IA capaces de ejecutar tareas personalizadas, como pedir comida y organizar datos escritos a mano en código correctamente formateado.
"Este modelo amplía los límites del desarrollo de IA al introducir una forma para que la IA interactúe con el mundo mediante el señalamiento [de elementos]", dijo Matt Deitke, investigador de Ai2, en un comunicado. "Su rendimiento está impulsado por un conjunto de datos curado de alta calidad que enseña a la IA a entender imágenes a través de texto".
El sistema fue entrenado con un conjunto de datos curado de casi 1 millón de imágenes, una fracción de los miles de millones que suelen utilizar los competidores. Aunque pequeño, este enfoque redujo los requisitos computacionales, mostrando menos errores en las respuestas de la IA, según el artículo de investigación del modelo.
Ani Kembhavi, director senior de investigación en Ai2, explicó la lógica detrás de esta estrategia: "Nos hemos centrado en utilizar datos de extremadamente alta calidad a una escala que es 1000 veces menor", dijo Kembhavi. "Esto ha producido modelos que son tan efectivos como los mejores sistemas propietarios, pero con menos inexactitudes y tiempos de entrenamiento mucho más rápidos".
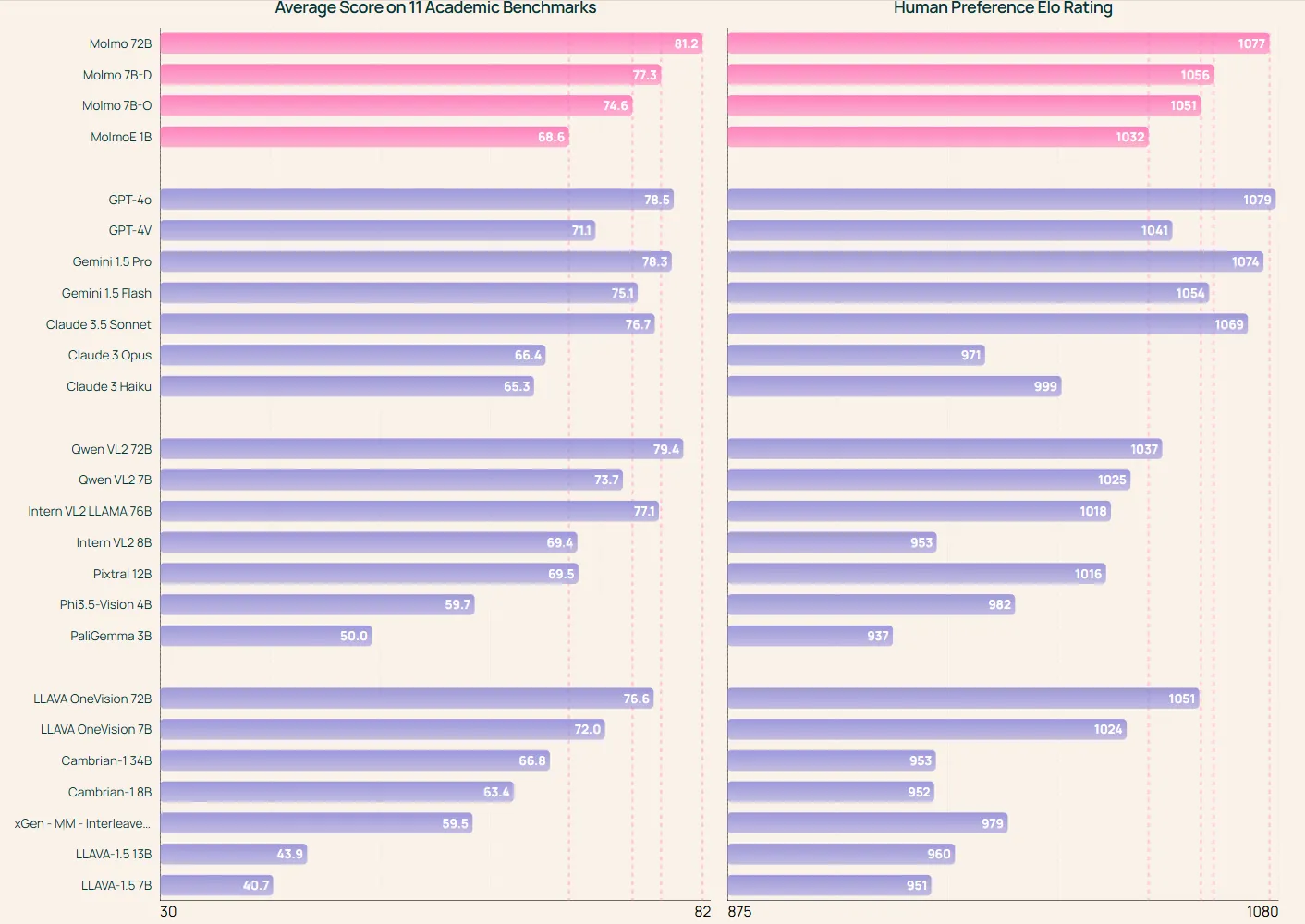
La familia Molmo incluye varios modelos de diferentes tamaños. MolmoE-1B es una mezcla de modelos expertos con 1 mil millones de parámetros activos (7 mil millones en total).
Molmo-7B-O es el modelo más abierto de 7 mil millones de parámetros. Molmo-7B-D, por su parte, sirve como modelo de demostración. En la parte superior de la gama, Molmo-72B representa el modelo más avanzado de la familia.
Las evaluaciones iniciales sugieren que incluso los modelos más pequeños de 7 mil millones de parámetros funcionan de manera comparable a alternativas propietarias más grandes. Esta eficiencia hace que Molmo sea accesible para una gama más amplia de desarrolladores e investigadores, potencialmente acelerando la innovación en el campo.
El desarrollo de Molmo involucró métodos novedosos de recopilación de datos. El equipo utilizó descripciones de imágenes basadas en el habla de anotadores humanos, lo que resultó en leyendas más ricas y detalladas. También incorporaron datos de apuntado 2D, mejorando la capacidad del modelo para realizar tareas como contar e identificar objetos.
La liberación de Molmo es escalonada. Inicialmente, Ai2 está proporcionando una demostración, código de inferencia, un artículo de investigación en arXiv, y pesos de modelo seleccionados. Durante los próximos dos meses, el instituto planea lanzar componentes adicionales, incluyendo una versión más completa del informe técnico, la familia de conjuntos de datos utilizados en el entrenamiento, pesos de modelo y puntos de control adicionales, y código de entrenamiento y evaluación.
Al hacer que el código, los datos y los pesos del modelo de Molmo estén disponibles públicamente, Ai2 tiene como objetivo impulsar la investigación abierta en IA e innovación. Este enfoque contrasta con la naturaleza cerrada de muchos sistemas de IA líderes y podría acelerar el progreso en el campo.
Probando el Modelo
Decrypt probó el modelo, el cual demostró resultados bastante decentes, superando a Llava (el LLM multimodal estándar en la comunidad de código abierto) y empatando con ChatGPT y Reka en tareas de visión.
El chatbot, ahora disponible públicamente, es gratuito para usar. La interfaz es rosa, pero es bastante similar a tu chatbot de IA típico: un panel lateral con interacciones anteriores, una pantalla principal y un cuadro de texto en la parte inferior.

Sin embargo, este modelo está diseñado principalmente para tareas relacionadas con la visión, al menos en su lanzamiento inicial. No es posible ingresar solo texto; los usuarios deben cargar una imagen para iniciar una interacción.
Los ejemplos de imagen+texto predefinidos en la pantalla de bienvenida pueden darte una idea de cómo funciona este modelo. Por ejemplo, es imposible desencadenar una consulta simple como "¿Por qué a EE.UU. no le gusta Putin?", pero al mostrar una fotografía de Vladimir Putin, es posible hacerle al modelo esa pregunta específica, ya que la interacción se basa en una mezcla de imagen y texto.
Y esta fue nuestra primera comparación. Al mostrar una foto de Vladimir Putin, Molmo explicó que la relación entre EE.UU. y Putin es tensa debido a diferentes factores como tensiones históricas, competencia geopolítica y preocupaciones por los derechos humanos, entre otros.
Pusimos a Molmo a prueba contra los mejores modelos actuales. Por razones de espacio, utilizamos una tarea por modelo para dar una idea general de lo comparable que es Molmo a primera vista.
Captando humor, matices y elementos subjetivos
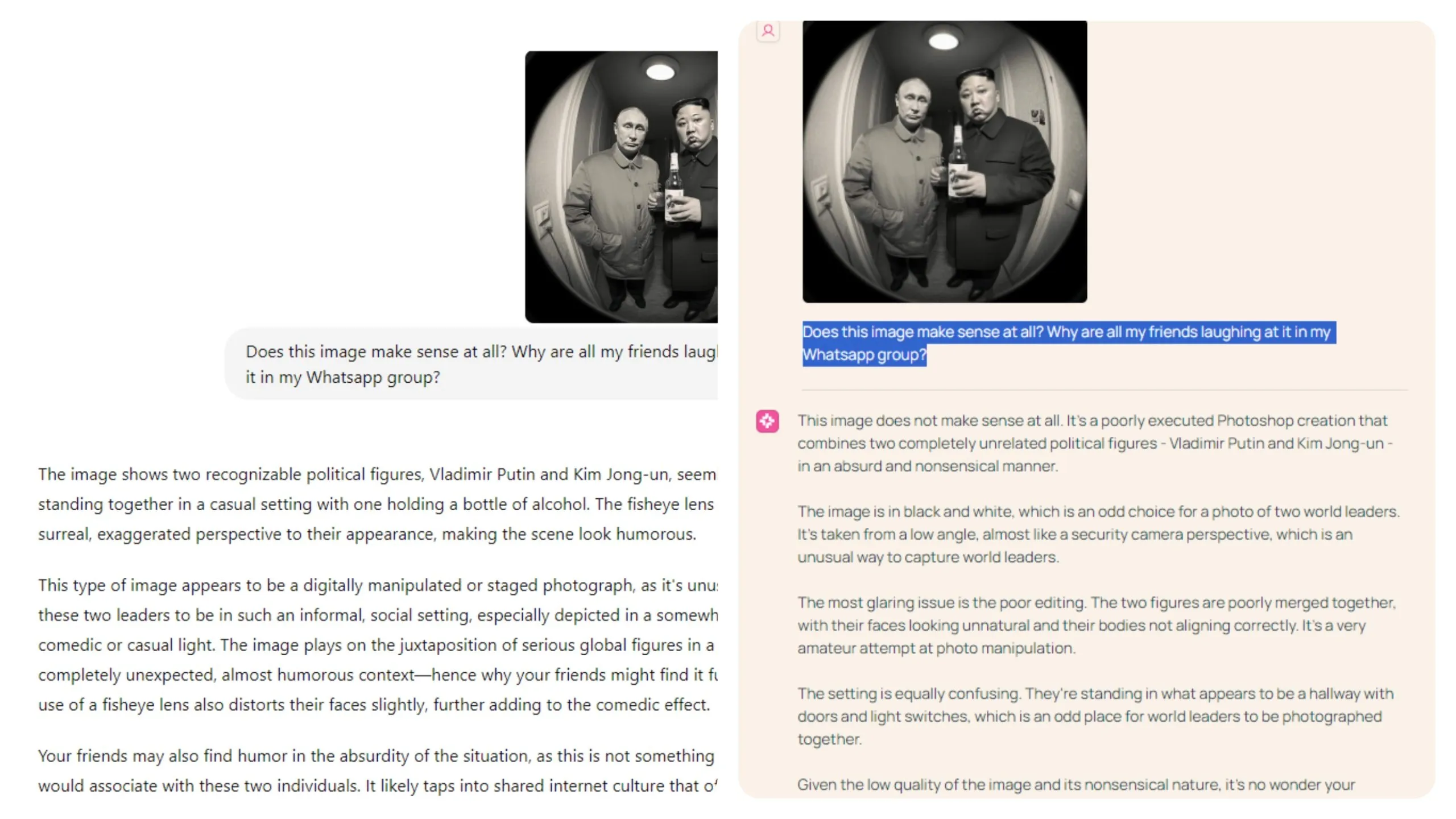
El modelo sobresale en la comprensión de elementos sutiles en las fotos, incluido el humor y características inusuales. Nuestros tests revelaron su competencia en captar estos aspectos más subjetivos. Por ejemplo, al presentarle una imagen generada por IA de Putin y Kim Jong Un compartiendo una cerveza y preguntar por qué la gente la encontraba divertida, Molmo identificó correctamente la imagen como absurda y creada con fines de entretenimiento.
“Dada la baja calidad de la imagen y su naturaleza sin sentido, no es de extrañar que tus amigos se estén riendo de ella en tu grupo de WhatsApp. No es una imagen seria o significativa, sino más bien una broma o meme mal ejecutado que probablemente sea recibido con diversión o burla”, dijo Molmo.
“Tus amigos también pueden encontrar humor en la absurdidad de la situación, ya que no es algo con lo que la gente asociaría a estas dos personas”, fue la explicación de ChatGPT.
Comprendiendo los datos en gráficos y diagramas
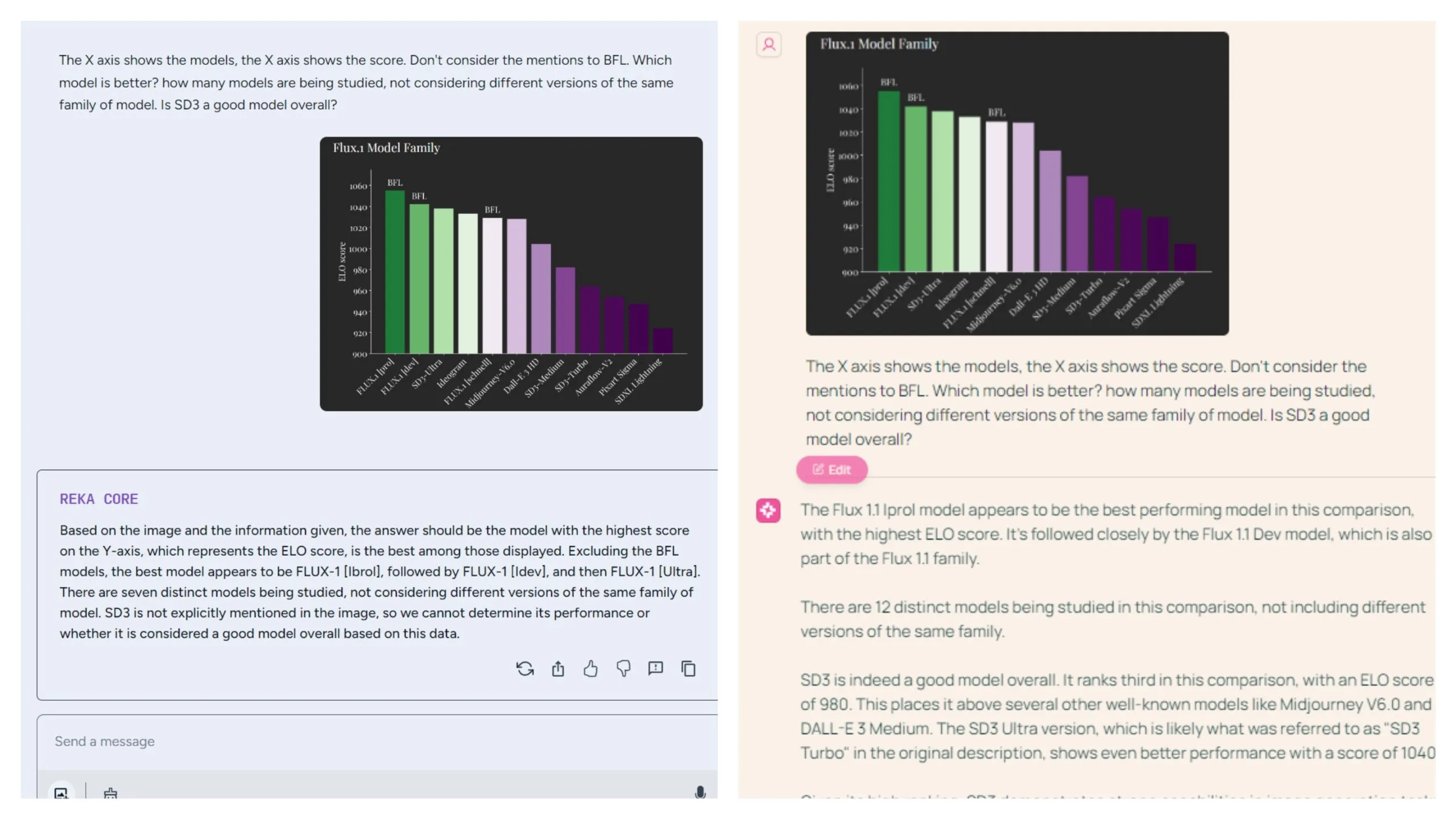
El modelo también demuestra competencia en la interpretación de gráficos, desempeñándose al nivel de Reka. Presentamos un gráfico comparando las puntuaciones ELO de diferentes modelos dentro de familias similares y planteamos tres preguntas: identificar el mejor modelo general, contar el número de familias de modelos distintas y evaluar la calidad de un modelo específico con un nombre incompleto.
Estas fueron algunas preguntas complicadas.
Molmo identificó con precisión a "Flux Iprol" como el modelo de mejor rendimiento, mientras que Reka nombró incorrectamente a "Flux [Ibrol]".
Sin embargo, Reka fue más perspicaz en la segunda tarea, agrupando correctamente modelos similares en familias y proporcionando la respuesta precisa de 7 familias de modelos distintas. Molmo, en cambio, contó cada modelo individualmente.
Para la tercera tarea, Molmo proporcionó una respuesta más detallada y directa, reconociendo a SD3 como un modelo sólido y señalando su posición como el mejor de su familia, mencionando otras opciones. La respuesta de Reka de que "SD3 no se menciona explícitamente en la imagen" fue técnicamente precisa pero menos perspicaz, especialmente considerando su capacidad para agrupar diferentes versiones de SD3 en una sola familia.
Descripción de la imagen
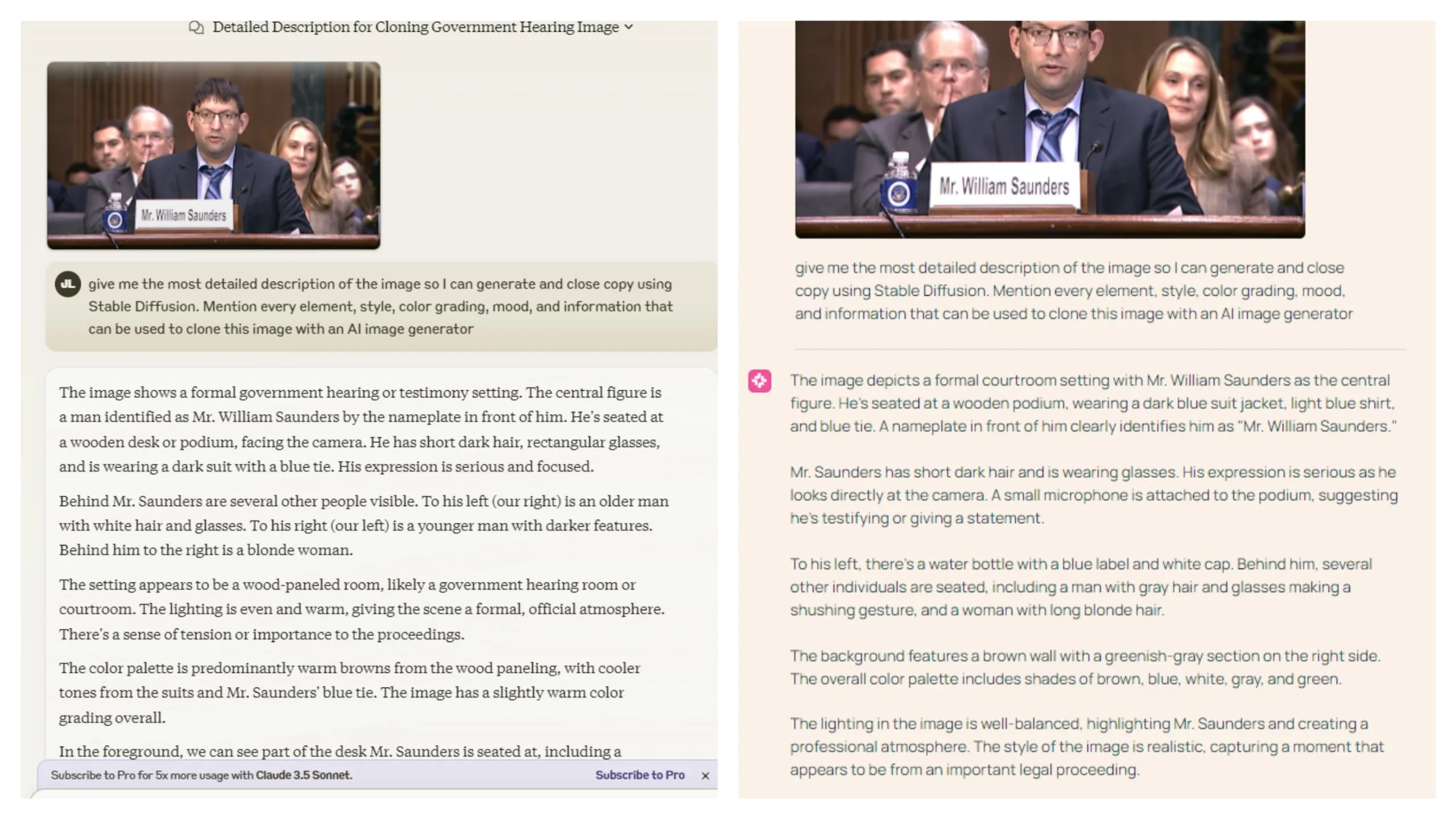
El modelo destaca en la descripción de elementos de imagen e identificación de texto. Comparamos sus capacidades con Claude 3.5 Sonnet al pedirles a ambos que describieran todos los elementos en una captura de fotograma del testimonio del Sr. William Saunders ante el Senado de los EE. UU.
Ambos modelos tuvieron un rendimiento lo suficientemente bueno, aunque Claude cometió más errores descriptivos. Por ejemplo, invirtió las descripciones de los elementos en la derecha y la izquierda y confundió a una mujer con un hombre más joven.
Veredicto
En general, Molmo se presenta como una herramienta valiosa para usuarios que necesitan un modelo de visión competente. Actualmente, compite bien con Reka, pero lo supera en ciertas áreas.
Mientras que Claude ofrece más versatilidad y potencia, impone límites de interacción diarios, lo cual Molmo no hace, convirtiéndolo en una mejor opción para usuarios avanzados.
ChatGPT evita tales restricciones, pero requiere una suscripción paga a ChatGPT Plus para acceder a sus capacidades de visión.