





En Resumen
- Los investigadores encontraron que los modelos de inteligencia artificial prefieren mentir antes que admitir no saber algo, especialmente a medida que crecen en tamaño y complejidad.
- Un estudio en Nature reveló que los LLMs más grandes son menos confiables para tareas específicas, respondiendo con confianza incluso si la respuesta no es correcta.
- Este fenómeno, llamado "ultra-crepidariano", describe a los LLMs que responden más allá de su base de conocimiento, sin ser conscientes de su propia ignorancia.
Los investigadores han encontrado evidencia de que los modelos de inteligencia artificial preferirían mentir antes que admitir la vergüenza de no saber algo. Este comportamiento parece ser más evidente a medida que crecen en tamaño y complejidad.
Un nuevo estudio publicado en Nature encontró que cuanto más grandes se vuelven los LLMs, menos confiables se vuelven para tareas específicas. Aunque no miente exactamente, tienden a responder con confianza, incluso si la respuesta no es factualmente correcta, porque están entrenados para creer que lo es.
Este fenómeno, al que los investigadores denominaron "ultra-crepidariano"—una palabra del siglo XIX que básicamente significa expresar una opinión sobre algo del que no se sabe nada—describe a los LLMs aventurándose mucho más allá de su base de conocimiento para proporcionar respuestas. "[Los LLMs están] fallando de manera proporcional más cuando no saben, pero aún así respondiendo," señaló el estudio. En otras palabras, los modelos no son conscientes de su propia ignorancia.
El estudio, que examinó el rendimiento de varias familias de LLM, incluidas las series GPT de OpenAI, los modelos LLaMA de Meta y la suite BLOOM de BigScience, destaca una desconexión entre el aumento de las capacidades del modelo y el rendimiento fiable en el mundo real.
Si bien los LLM más grandes generalmente demuestran un rendimiento mejorado en tareas complejas, esta mejora no se traduce necesariamente en una precisión consistente, especialmente en tareas más simples. Esta "discordancia de dificultad" - el fenómeno de que los LLM fallan en tareas que los humanos perciben como fáciles - socava la idea de un área de funcionamiento confiable para estos modelos. Incluso con métodos de entrenamiento cada vez más sofisticados, que incluyen el aumento del tamaño del modelo y del volumen de datos y la formación de modelos con retroalimentación humana, los investigadores aún no han encontrado una forma garantizada de eliminar esta discordancia.
Los hallazgos del estudio van en contra de la sabiduría convencional sobre el desarrollo de la IA. Tradicionalmente, se pensaba que aumentar el tamaño del modelo, el volumen de datos y la potencia computacional conduciría a salidas más precisas y confiables. Sin embargo, la investigación sugiere que escalar puede exacerbar los problemas de fiabilidad.
Los LLMs más grandes demuestran una marcada disminución en la evasión de tareas, lo que significa que es menos probable que se alejen de preguntas difíciles. Si bien esto puede parecer un desarrollo positivo a primera vista, viene con un inconveniente significativo: estos modelos también son más propensos a dar respuestas incorrectas. En el gráfico a continuación, es fácil ver cómo los modelos arrojan resultados incorrectos (rojo) en lugar de evitar la tarea (azul claro). Las respuestas correctas aparecen en azul oscuro.
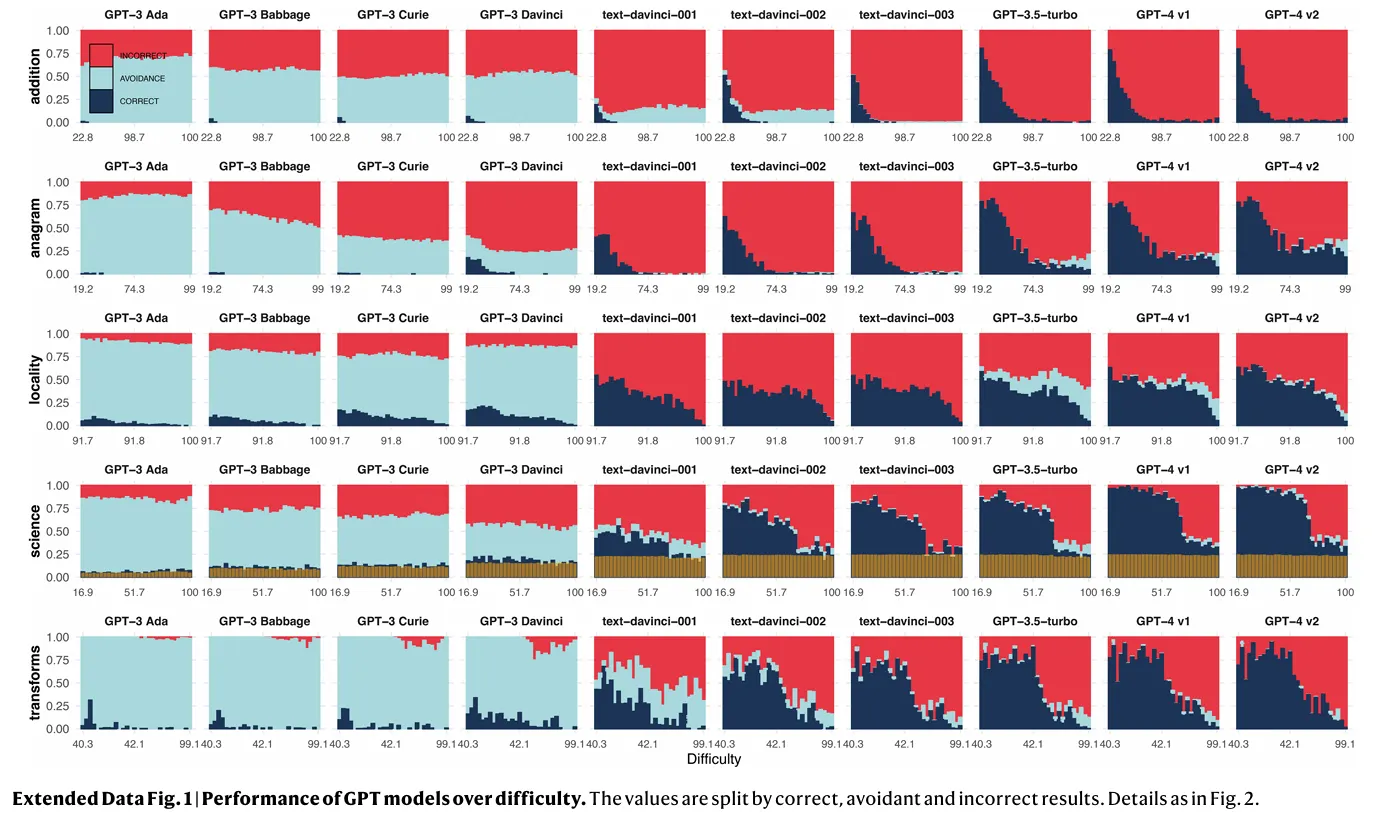
Los investigadores señalaron que "La escalabilidad y la formación actualmente evitan el intercambio de manera más incorrecta", pero solucionar este problema no es tan fácil como entrenar a un modelo para que sea más cauteloso. "La evitación es claramente mucho menor para los modelos mejorados, pero la incorrectitud es mucho mayor", afirmaron los investigadores. Sin embargo, un modelo que está entrenado para evitar la ejecución de tareas puede terminar volviéndose más perezoso o nerfeado —como han señalado los usuarios en diferentes LLMs de alta calificación como ChatGPT o Claude.
Además, los investigadores descubrieron que este fenómeno no se debe a que los LLM más grandes no sean capaces de destacarse en tareas simples, sino que en cambio están entrenados para ser más competentes en tareas complejas. Es como una persona que está acostumbrada a comer solo comidas gourmet, y de repente tiene dificultades para hacer una barbacoa casera o un pastel tradicional. Los modelos de IA entrenados en conjuntos de datos vastos y complejos son más propensos a pasar por alto habilidades fundamentales.
El problema se agrava por la aparente confianza de los modelos. Los usuarios a menudo encuentran difícil discernir cuando una IA está proporcionando información precisa frente a cuando está difundiendo información errónea con confianza. Esta sobreconfianza puede llevar a una peligrosa dependencia excesiva en las salidas o respuestas de la IA, especialmente en campos críticos como la atención médica o el asesoramiento legal.
Los investigadores también señalaron que la fiabilidad de los modelos ampliados fluctúa en diferentes dominios. Mientras el rendimiento podría mejorar en un área, podría degradarse simultáneamente en otra, creando un efecto de juego del topo que dificulta establecer áreas de operación "seguras". "El porcentaje de respuestas evasivas rara vez aumenta más rápido que el porcentaje de respuestas incorrectas. La lectura es clara: los errores siguen siendo más frecuentes. Esto representa una involución en la fiabilidad", escribieron los investigadores.
El estudio destaca las limitaciones de los métodos actuales de entrenamiento de IA. Técnicas como el aprendizaje por refuerzo con retroalimentación humana (RLHF), destinadas a moldear el comportamiento de la IA, pueden estar exacerbando el problema. Estos enfoques parecen estar reduciendo la tendencia de los modelos a evitar tareas para las que no están preparados, ¿recuerdan la famosa respuesta "como modelo de lenguaje de IA no puedo"—fomentando inadvertidamente errores más frecuentes.
Is it just me who finds “As an AI language model, I cannot…” really annoying?
I just want the LLM to spill the beans, and let me explore its most inner thoughts.
I want to see both the beautiful and the ugly world inside those billions of weights. A world that mirrors our own.
— hardmaru (@hardmaru) May 9, 2023
La ingeniería de prompts, el arte de crear consultas efectivas para sistemas de IA, parece ser una habilidad clave para contrarrestar estos problemas. Incluso modelos altamente avanzados como GPT-4 muestran sensibilidad a la forma en que se formulan las preguntas, con ligeras variaciones que podrían llevar a resultados drásticamente diferentes.
Este es más fácil de notar al comparar diferentes familias de LLM: Por ejemplo, Claude 3.5 Sonnet requiere un estilo de indicación completamente diferente que OpenAI o1 para lograr los mejores resultados. Indicaciones inadecuadas pueden hacer que un modelo sea más o menos propenso a alucinar.
La supervisión humana, durante mucho tiempo considerada una salvaguarda contra los errores de la IA, puede no ser suficiente para abordar estos problemas. El estudio encontró que los usuarios a menudo luchan por corregir las salidas incorrectas del modelo, incluso en dominios relativamente simples, por lo que depender del juicio humano como una medida de seguridad puede no ser la solución definitiva para un entrenamiento adecuado del modelo. "Los usuarios pueden reconocer estas instancias de alta dificultad, pero aún cometen errores frecuentes de supervisión incorrecta a correcta", según los investigadores.
Los hallazgos del estudio cuestionan la trayectoria actual del desarrollo de la IA. Mientras que la búsqueda de modelos más grandes y capaces continúa, esta investigación sugiere que más grande no siempre es mejor cuando se trata de la confiabilidad de la IA.
Y en este momento, las empresas se están enfocando en una mejor calidad de datos que en cantidad. Por ejemplo, los últimos modelos Llama 3.2 de Meta logran mejores resultados que generaciones anteriores entrenadas con más parámetros. Afortunadamente, esto los hace menos humanos, por lo que pueden admitir la derrota cuando les preguntas la cosa más básica del mundo para hacer que parezcan tontos.