





En Resumen
- Investigadores descubrieron que los modelos de IA desarrollan habilidades antes de lo que las pruebas estándar sugieren, lo que podría cambiar la forma de evaluar la IA.
- Los modelos de IA muestran habilidades "ocultas" durante el entrenamiento, emergiendo repentinamente cuando se utilizan métodos de prompting adecuados antes de lo esperado.
- El fenómeno de "emergencia oculta" podría alterar la seguridad y evaluación de la IA, ya que las pruebas tradicionales subestiman las capacidades del modelo, incluso las preocupantes.
Los modelos de IA modernos poseen capacidades ocultas que emergen de manera súbita y consistente durante el entrenamiento, pero estas habilidades permanecen ocultas hasta que se les solicita de maneras específicas, según nueva investigación de Harvard y la Universidad de Michigan.
El estudio, que analizó cómo los sistemas de IA aprenden conceptos como color y tamaño, reveló que los modelos a menudo dominan estas habilidades mucho antes de lo que sugieren las pruebas estándar—un hallazgo con importantes implicaciones para la seguridad y desarrollo de la IA.
"Nuestros resultados demuestran que medir las capacidades de un sistema de IA es más complejo de lo que se pensaba anteriormente", dice el paper de investigación. "Un modelo puede parecer incompetente cuando se le dan prompts estándar mientras que en realidad posee habilidades sofisticadas que solo emergen bajo condiciones específicas".
Este avance se une a un creciente cuerpo de investigación destinado a desmitificar cómo los modelos de IA desarrollan capacidades.
Los investigadores de Anthropic revelaron el "dictionary learning", una técnica que mapeó millones de conexiones neuronales dentro de su modelo de lenguaje Claude para conceptos específicos que la IA comprende, según reportó Decrypt a principios de este año.
Si bien los enfoques difieren, estos estudios comparten un objetivo común: traer transparencia a lo que principalmente se ha considerado la "caja negra" del aprendizaje de la IA.
Los investigadores realizaron extensos experimentos utilizando modelos de difusión—la arquitectura más popular para IA generativa. Mientras rastreaban cómo estos modelos aprendían a manipular conceptos básicos, descubrieron un patrón consistente: las capacidades emergían en fases distintas, con un punto de transición agudo que marcaba cuando el modelo adquiría nuevas habilidades.
Los modelos mostraron dominio de conceptos hasta 2.000 pasos de entrenamiento antes de lo que las pruebas estándar podían detectar. Los conceptos fuertes emergieron alrededor de los 6.000 pasos, mientras que los más débiles aparecieron alrededor de los 20.000 pasos.
Cuando los investigadores ajustaron la "señal de concepto", la claridad con la que las ideas se presentaban en los datos de entrenamiento, encontraron correlaciones directas con la velocidad de aprendizaje.
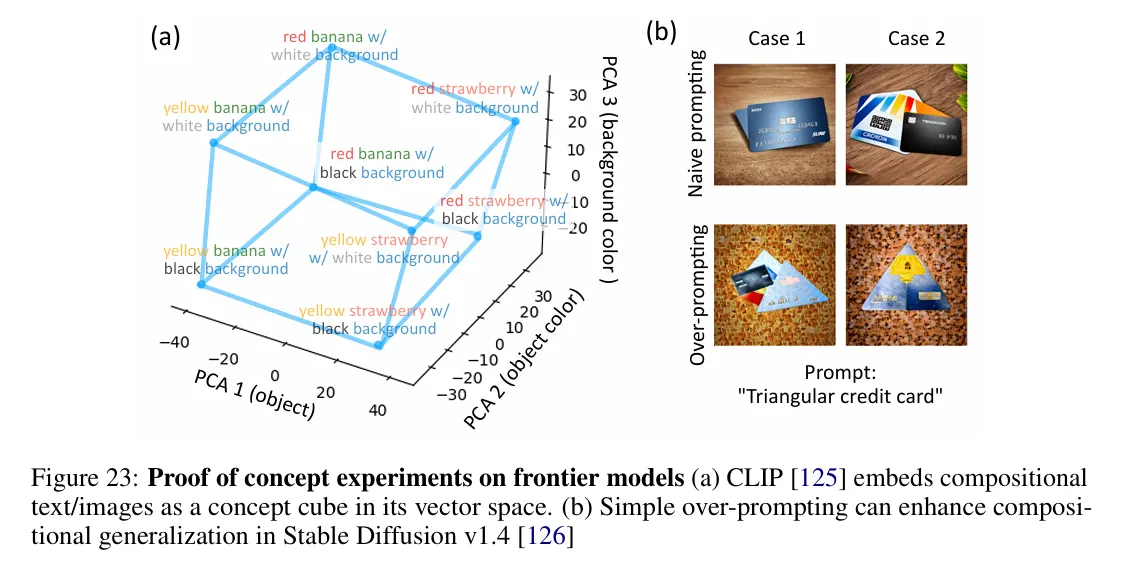
Los métodos alternativos de prompting podían extraer de manera confiable capacidades ocultas mucho antes de que aparecieran en las pruebas estándar.
Este fenómeno de "emergencia oculta" tiene implicaciones significativas para la seguridad y evaluación de la IA. Los benchmarks tradicionales pueden subestimar dramáticamente lo que los modelos pueden realmente hacer, potencialmente pasando por alto tanto capacidades beneficiosas como preocupantes.
Quizás lo más intrigante es que el equipo descubrió múltiples formas de acceder a estas capacidades ocultas. Usando técnicas que denominaron "intervención lineal latente" y "overprompting", los investigadores podían extraer de manera confiable comportamientos sofisticados de los modelos mucho antes de que estas habilidades aparecieran en las pruebas estándar.
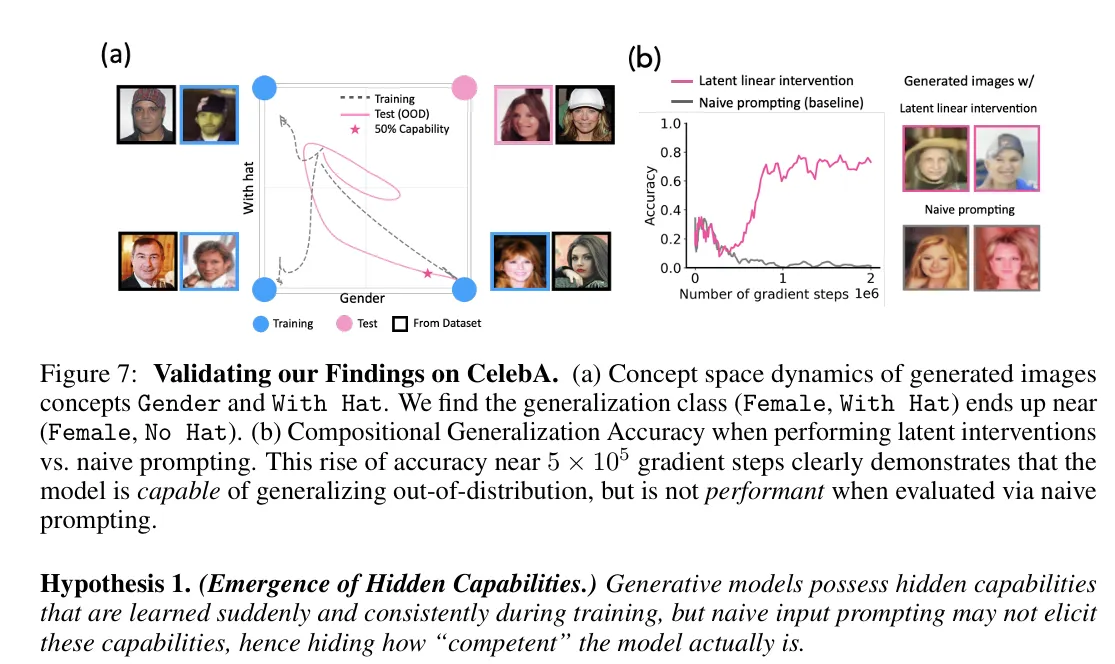
En otro caso, los investigadores encontraron que los modelos de IA aprendieron a manipular características complejas como la presentación de género y las expresiones faciales antes de que pudieran demostrar de manera confiable estas habilidades a través de prompts estándar.
Por ejemplo, los modelos podían generar con precisión "mujeres sonriendo" u "hombres con sombreros" individualmente antes de que pudieran combinar estas características—sin embargo, un análisis detallado mostró que habían dominado la combinación mucho antes. Simplemente no podían expresarlo a través del prompting convencional.
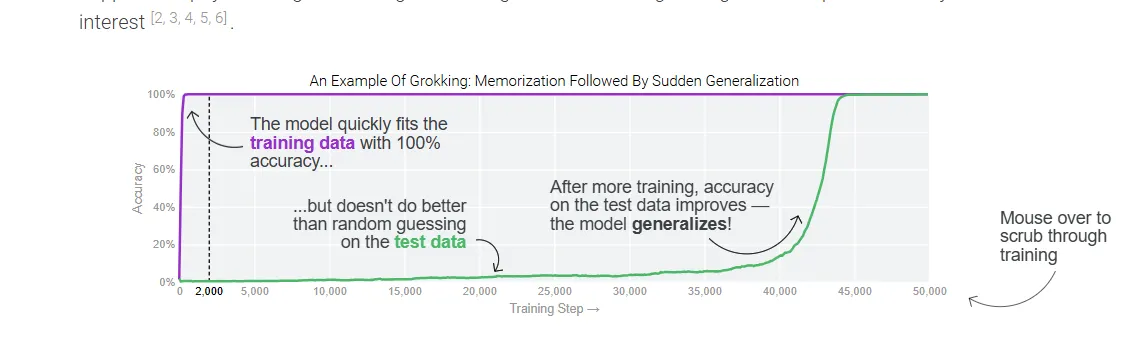
La emergencia súbita de capacidades observada en este estudio podría inicialmente parecer similar al grokking—donde los modelos demuestran abruptamente un rendimiento perfecto en las pruebas después de un entrenamiento prolongado—pero hay diferencias clave.
Mientras que el grokking ocurre después de una meseta de entrenamiento e implica el refinamiento gradual de representaciones en la misma distribución de datos, esta investigación muestra capacidades emergiendo durante el aprendizaje activo e involucrando generalización fuera de la distribución.
Los autores encontraron transiciones agudas en la capacidad del modelo para manipular conceptos de nuevas maneras, sugiriendo cambios de fase discretos en lugar de las mejoras graduales de representación vistas en el grokking.
En otras palabras, parece que los modelos de IA internalizan conceptos mucho antes de lo que pensábamos, simplemente no pueden mostrar sus habilidades—algo así como algunas personas pueden entender una película en un idioma extranjero pero aún luchan por hablarlo correctamente.
Para la industria de la inteligencia artificial, esto es un arma de doble filo. La presencia de capacidades ocultas indica que los modelos podrían ser más potentes de lo que se pensaba anteriormente. Sin embargo, también demuestra lo difícil que es entender y controlar completamente lo que pueden hacer.
Las empresas que desarrollan LLMs y generadores de imágenes pueden necesitar revisar sus protocolos de prueba.
Los puntos de referencia tradicionales, aunque siguen siendo valiosos, pueden necesitar ser complementados con métodos de evaluación más sofisticados que puedan detectar capacidades ocultas.
Editado por Sebastian Sinclair