





AI enthusiasts, rejoice: There’s a new multimodal, large learning model for you to play with.
Seattle-based non-profit AI research outfit, the Allen Institute for AI (Ai2), just introduced Molmo, a family of multimodal artificial intelligence models that promise to rival the capabilities of proprietary vision-based offers from major tech companies like Openai and Anthropic.
Multimodal refers to the ability to handle different data types, including text, images, audio, video, and even sensory info.
On Tuesday, Molmo debuted without the fanfare of all the major AI models but with all the bells and whistles of any state-of-the-art vision model.
The system demonstrated remarkable proficiency in interpreting visual data, from everyday objects to complex charts and messy whiteboards.
In a video demonstration, Ai2 showcased Molmo's ability to create AI agents capable of executing personalized tasks, such as ordering food and organizing handwritten data into properly formatted code.
"This model pushes the boundaries of AI development by introducing a way for AI to interact with the world through pointing [out elements].” Matt Deitke, a researcher at Ai2, said in a statement. “Its performance is driven by a remarkably high-quality curated dataset that teaches AI to understand images through text."
The system was trained on a curated dataset of nearly 1 million images—a fraction of the billions typically used by competitors. Although small, this approach reduced computational requirements, showing fewer errors in AI responses, according to the model’s research paper.
Ani Kembhavi, senior director of research at Ai2, explained the rationale behind this strategy: "We've focused on using extremely high-quality data at a scale that is 1000 times smaller, Kembhavi said. "This has produced models that are as effective as the best proprietary systems, but with fewer inaccuracies and much faster training times."
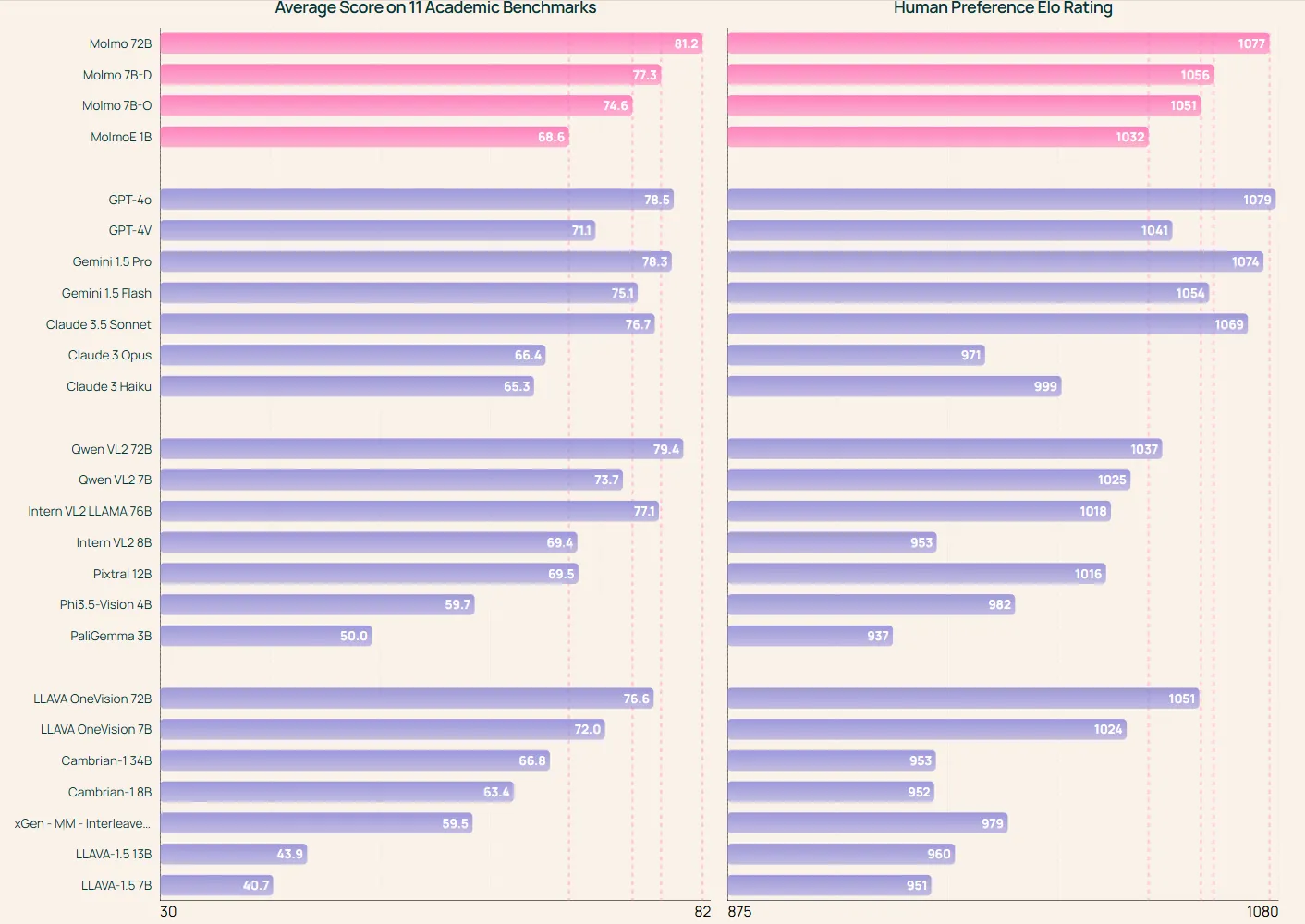
The Molmo family includes several models of varying sizes. MolmoE-1B is a mixture of expert models with 1 billion active parameters (7 billion total).
Molmo-7B-O is the most open 7 billion parameter model. Molmo-7B-D, meanwhile, serves as a demonstration model. At the top of the range, Molmo-72B represents the most advanced model in the family.
Initial evaluations suggest that even the smaller 7 billion parameter models perform comparably to more significant proprietary alternatives. This efficiency makes Molmo accessible to a broader range of developers and researchers, potentially accelerating innovation in the field.
Molmo's development involved novel data collection methods. The team used speech-based image descriptions from human annotators, resulting in richer and more detailed captions. They also incorporated 2D pointing data, enhancing the model's ability to perform tasks like counting and object identification.
The release of Molmo is phased. Initially, Ai2 is providing a demo, inference code, a research paper on arXiv, and select model weights. Over the next two months, the institute plans to release additional components, including a more comprehensive version of the technical report, the family of datasets used in training, additional model weights and checkpoints, and training and evaluation code.
By making Molmo's code, data, and model weights publicly available, Ai2 aims to boost open AI research and innovation. This approach contrasts with the closed nature of many leading AI systems and could accelerate progress in the field.
Testing The Model
Decrypt tested the model, which demonstrated fairly decent results, outperforming Llava (the standard multimodal LLM in the open-source community) and matching ChatGPT and Reka in vision tasks.
The chatbot, now publicly available, is free to use. The interface is pink, but it’s pretty similar to your typical AI chatbot: A side panel with previous interactions, a main screen, and a text box in the lower part.

However, this model is primarily designed for vision-related tasks, at least in its initial release. Text-only input is not possible; users must upload an image to initiate an interaction.
The pre-prompted image+text samples on the welcome screen may give you a clue about how this model works. For example, it’s impossible to trigger a simple query like “Why doesn’t America like Putin?” but prompting a photograph of Vladimir Putin makes it possible to ask the model that specific question as the interaction is based on a mixture of image and text.
And this was our first comparison. Upon showing a photo of Vladimir Putin, Molmo explained that the relationship between America and Putin is tense due to different factors like Historical tensions, Geopolitical competition and Human rights concerns among others.
We put Molmo to the test against today’s best models. For space reasons, we used one task per model to give a broad idea of how comparable Molmo is at first glance.
Catching humor, nuances and subjective elements
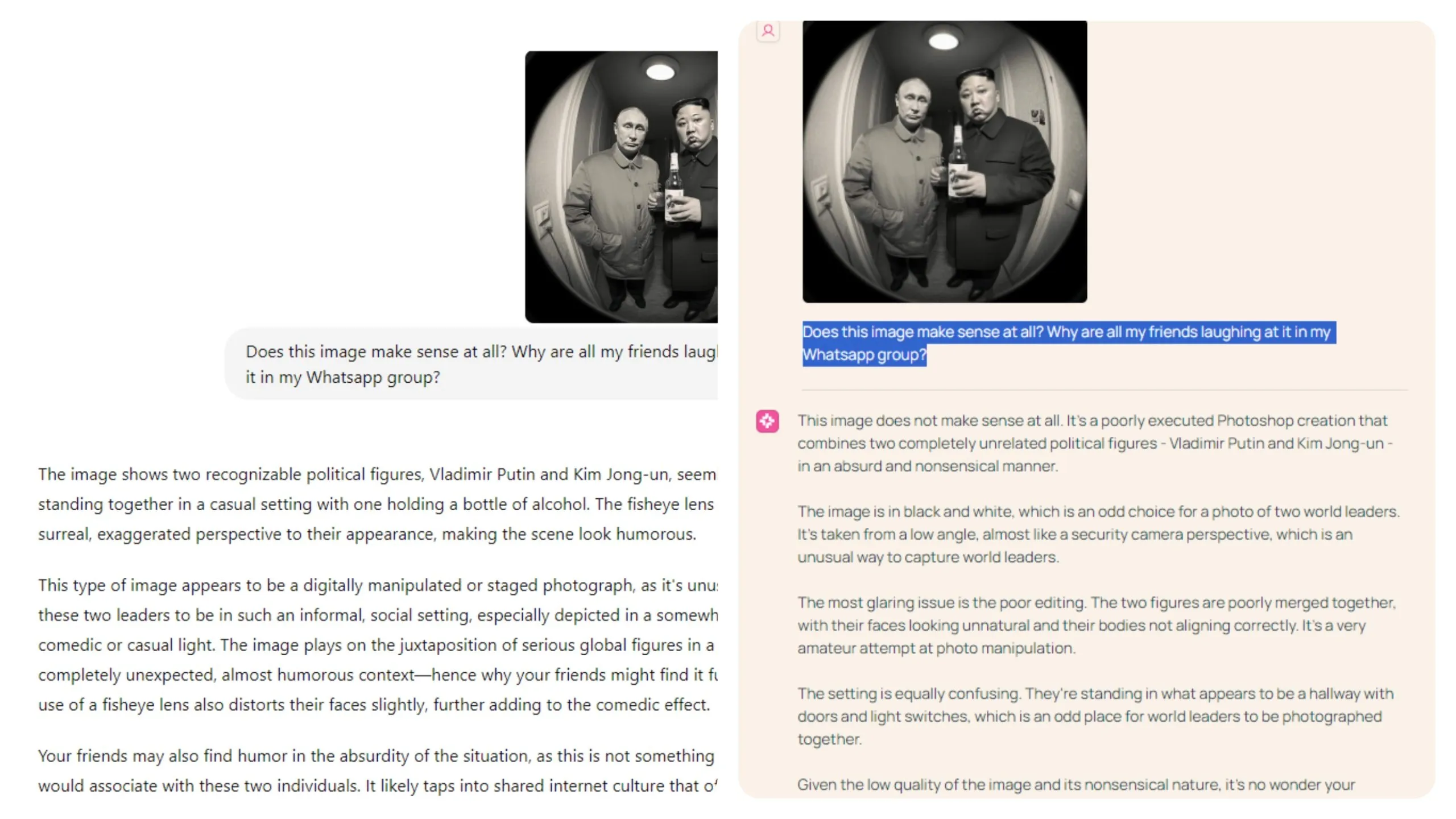
The model excels at understanding subtle elements in photos, including humor and unusual features. Our tests revealed its proficiency in grasping these more subjective aspects. For example, when presented with an AI-generated image of Putin and Kim Jong Un sharing a beer and asked why people found it amusing, Molmo correctly identified the image as nonsensical and created for entertainment purposes.
“Given the low quality of the image and its nonsensical nature, it's no wonder your friends are laughing at it in your WhatsApp group. It's not a serious or meaningful image, but rather a poorly executed joke or meme that's likely to be met with amusement or mockery,” Molmo said.
“Your friends may also find humor in the absurdity of the situation, as this is not something people would associate with these two individuals,” was ChatGPT’s explanation
Understanding data in charts and graphs
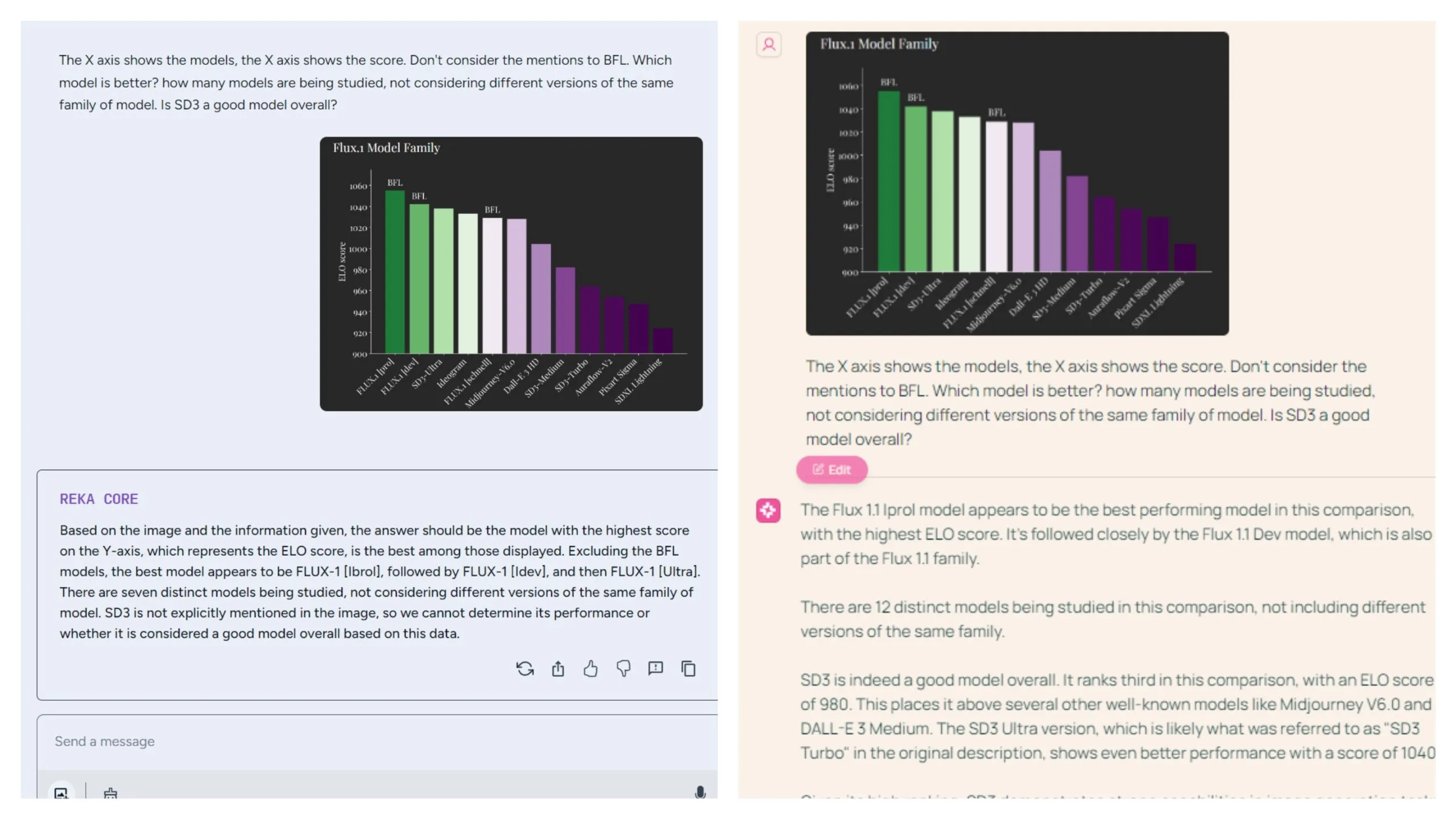
The model also demonstrates proficiency in interpreting charts, performing on par with Reka. We presented a chart comparing ELO scores of different models within similar families and posed three questions: identifying the best overall model, counting the number of distinct model families, and evaluating the quality of a specific model with an incomplete name.
These were some tricky questions.
Molmo accurately identified "Flux Iprol" as the top-performing model, while Reka incorrectly named "Flux [Ibrol]."
However, Reka better discerned the nuances in the second task, correctly grouping similar models into families and providing the accurate answer of 7 distinct model families. Molmo, in contrast, counted each model individually.
For the third task, Molmo provided a more nuanced and direct response, acknowledging SD3 as a strong model and noting its position as the best in its family while mentioning other options. Reka's reply that "SD3 is not explicitly mentioned in the image" was technically accurate but less insightful, especially considering its ability to group different SD3 versions into a single family.
Image description
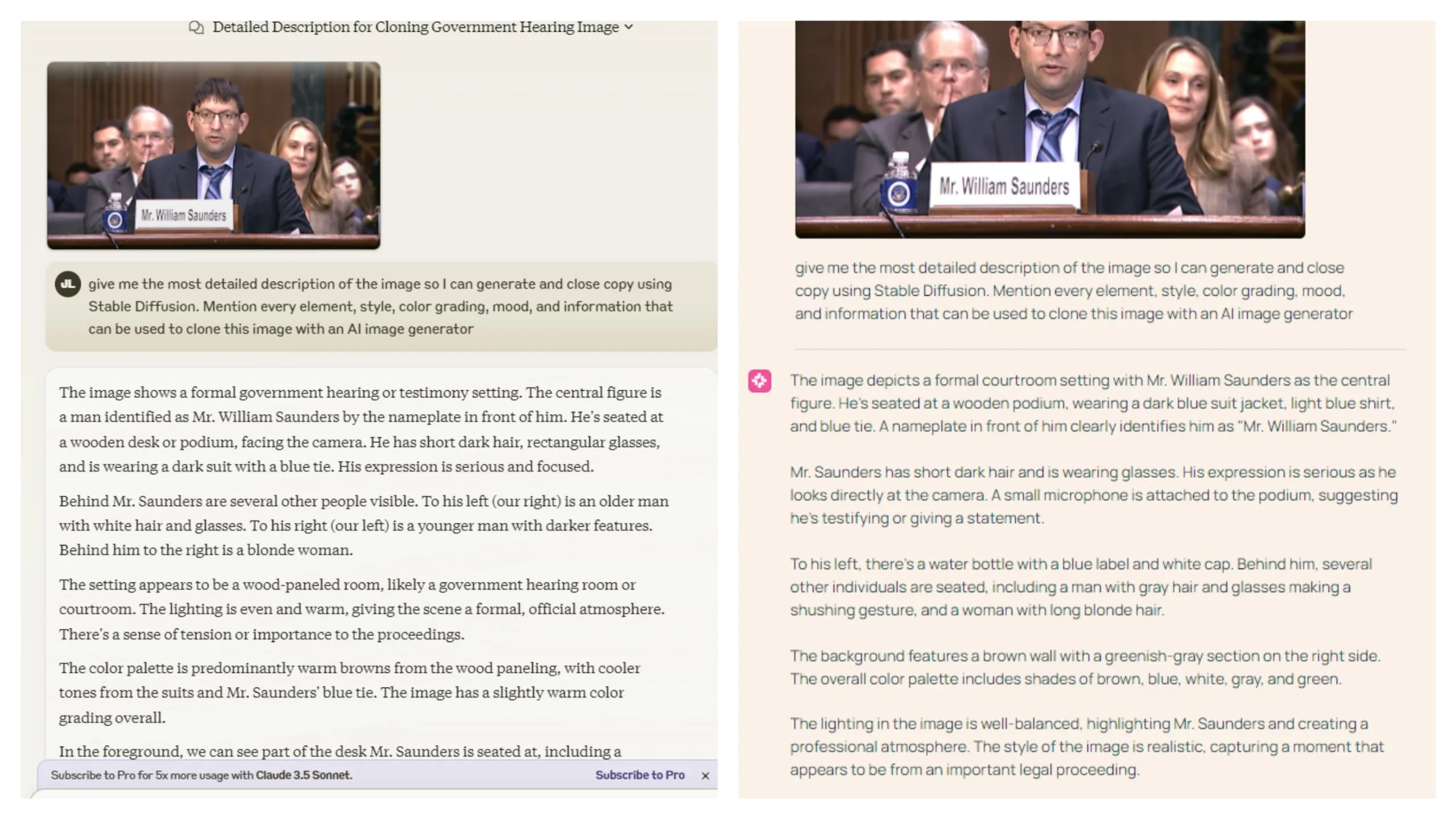
The model excels at describing image elements and identifying text. We compared its capabilities to Claude 3.5 Sonnet by asking both to describe all elements in a frame capture of Mr. William Saunders' testimony to the US Senate.
Both models performed well enough, though Claude made more descriptive errors. For instance, it reversed the descriptions of elements on the right and left and mistook a woman for a younger man.
Verdict
Overall, Molmo shows promise as a valuable tool for users requiring a proficient vision model. It currently competes well with Reka, but it is outperforming it in certain areas.
While Claude offers more versatility and power, it imposes daily interaction limits, which Molmo does not, making it a better option for power users.
ChatGPT avoids such restrictions but requires a paid ChatGPT Plus subscription to access its vision capabilities.